29. 학습의 단계_n8n - 9일차 - (SQL쿼리 예제 복습)
1단계. 학습의 단계
1. AWS Bedrock
첫번째 강의) Building Multi-Agentic AI Workflows on AWS Bedrock: 수강완료 (2025/4/13~04/16)
두번째 강의) Learn Agentic AI Basics, Amazon Bedrock Multi-Agent Framework (2025/4/29~06/11)
2. N8N
I. 강의 선택의 이유 / 수강 전 기대하는 부분
(중략)
이번 강의는 개념을 많이 알아보고 깨우치는 강의가 되기 보다는, "어? 그럼 이런것도 만들 수 있겠네? 어, 이거 만들어보고 싶다"라는 생각이 계속 드는 강의가 되기를 희망한다. 강의 완강까지 시간이 다소 걸려도 된다. 강의를 듣다가 배운 내용을 십분 활용하여 수강 중간에라도 toy project를 시도해보면 좋겠다.
II. 수업내용
1일차(25/6/11): Rapid API, n8n(rapid api, chat gpt api, firecrawl api)
1) 2강. "난생 첫 API 호출!" - API로 진짜 AI를 경험하다
2) 3강. "API라는 신세계" - 다양한 AI 활용 및 기초 구조
2일차(25/6/12~13): AI 챗봇, Tool 연동, 혼자서 두 개 에이전트를 만들어서 피드백 루프 구성 중.
3일차(25/6/20): 피드백 루프 구성 시도 후, 다시 강의 내용으로 복귀함. (네이버 API, claude API 연결)
3) 4강. "AI 에이전트, 1분 컷?" - 나만의 AI 비서 만들기
4일차(25/6/22~24): 5강 시작
4) 5강. "AI 에이전트 실사례" - 음성부터 텔레그램까지 손쉽게 연동
5일차(25/6/25~7/8)
5) 6강. "대규모 자동화의 힘" - 꿈꾸던 실전 데이터 수집과 처리
6) 7강. "워크플로우로 인터넷 정보 수집" - N8N 템플릿 활용 및 비즈니스 기획
6일차(25/7/8)
7) 8강. "정보의 정리정돈" - IDE 활용과 프롬프트 관리
8) 9강. "AI, 판단을 부탁해!" - AI 기반 의사결정 시스템
7일차(25/7/9)
9) 10강. "나만의 API 만들기" - Workflow 와 Webhook 활용
10) 11강. "우리 팀" - Workflow 와 Webhook 활용
11) 12강. "우리 팀 지식창고 구축" - 벡터 임베딩 실습
8일차(25/7/10)
12) 13강. "우리 팀 전용 슈퍼 채팅앱" - AI 서비스 배포와 운영
13) 14강. "이제부턴 html을 쉽게 만들자" - AI로 간단한 웹사이트는 직접 구현하기
14) 15강. "가장 가치 있던 프로젝트들" - AI로 만드는 쉽고 고부가가치 높은 제안들 및 조언
8일차(25/7/14)
최대한 학습 계획표에 맞춰 수업을 완강하였다. 이 과정에서 직접 수행하지 못했던 몇 가지 예제들이 있는데, 그 중에서도 LLM을 활용하여 SQL쿼리를 작성하고, 이를 기반으로 DB를 검색하는 하나의 예제와, Pinecone과 NotebookLM을 통해 벡터 임베딩 (AWS Bedrock 관점에서 보면 Knowledge base와 Opensearch)을 수행하는 예제, 총 두 가지는 꼭 수행해보고 싶었다.
15) 복습 - 예제#1. SQL 쿼리를 자동화하는 '11강' 내용 복습
먼저 DB 구성을 위해 Supabase에 계정을 생성했다.

신규로 프로젝트를 생성하고 Table Editor에 접속하면 아래와 같이 아무런 화면이 나오지 않는다.

강사 분은 공공데이터포털에서 의미있는 규모의 DB를 쉽게 획득할 수 있다고 했다. 공공데이터포털에 접속하여 관심있는 자료인 '거래주체별 주택거래 현황, 행정구역별 주택거래 현황' 두 가지 파일을 다운로드받는다.


또한 다운로드 받은 파일을 내가 필요한 데이터들 중심으로 가공하는 것 또한 필요한 작업이다. 현재는 예제 테스트를 위해서 csv 파일을 직접 수정하여 원하는 형태로 가공하겠으나, 만약 해당 공공데이터를 기반으로 자동화된 서비스를 구축하려고 한다면, 원본파일 그대로를 가져와서 파이썬 pandas 등으로 2차 가공하는 과정 또한 자동화해야한다. 그렇지 않으면 매번 원본데이터를 DB로 옮겨올 때마다 수동으로 데이터 가공 과정을 거쳐야 하기 때문에 지속적으로 DB관리가 소홀해질 수 있다.
데이터를 열어보니 integer (숫자)형식으로 들어가야할 데이터 중 몇몇 정보가 "###"과 같이 String(문자)로 추가된 것을 볼 수 있다. 이러한 포맷 문제는 일일이 수동으로 바꾸지 않고, SQL로 한 번에 수정할 수 있는지 확인할 것이다.

원하는 형태로 데이터를 가공했다면 '다른이름으로 저장'을 클릭한 후 'UTF-8'형식으로 csv 저장하도록 한다. 이렇게 해야 DB 생성 시 한글이 깨져 보이지 않는다.


DB 생성 시에는 반드시 하나의 primary key (=identifier, 고유식별자)를 선택해주어야 한다.

두 개의 csv 파일을 각각 DB 내 Table로 변환하였다.
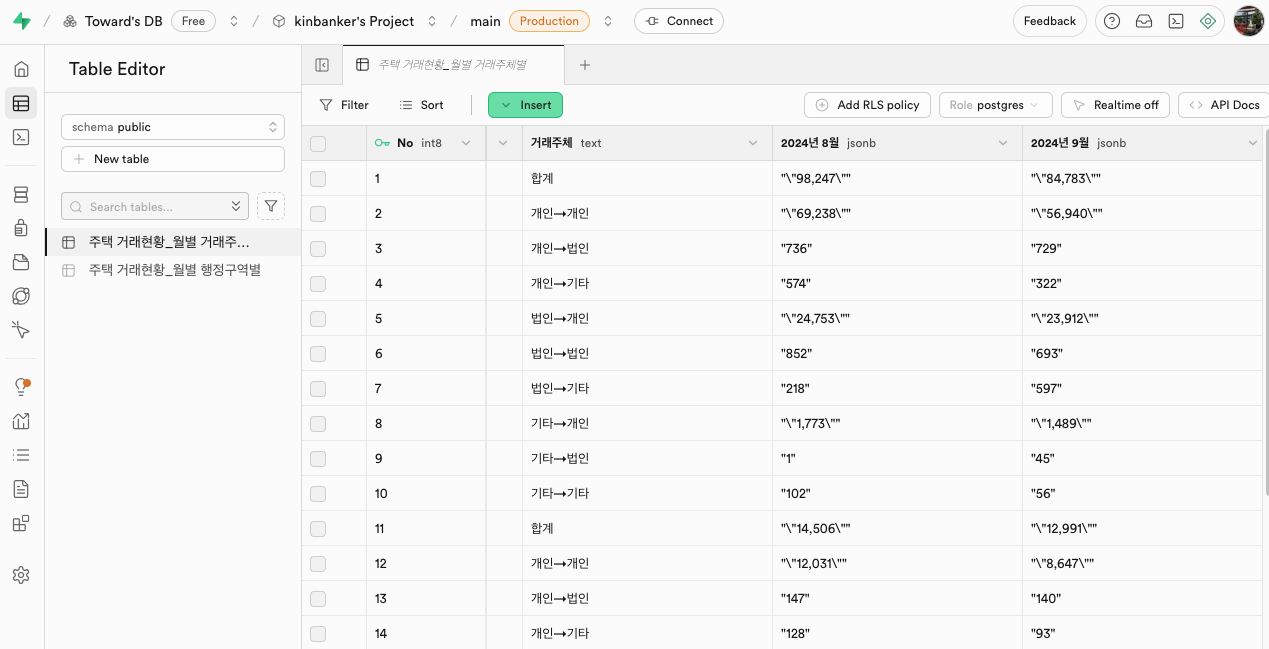
이제 SQL 쿼리 작성을 통해서, 상단에 지적한 문제인 "##,###"와 같은 형식을 ##,###처럼 변경하는 작업을 한다. SQL 쿼리 작성을 위해, 위 테이블 중 일부를 캡쳐하여 GROK에게 SQL Query 작성을 요청했고, 다음과 같이 정상 동작하는 쿼리를 얻었다.
UPDATE "주택 거래현황_월별 행정구역별"
SET
"2024년 8월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2024년 8월"::TEXT, ',', '')) AS INTEGER)),
"2024년 9월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2024년 9월"::TEXT, ',', '')) AS INTEGER)),
"2024년 10월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2024년 10월"::TEXT, ',', '')) AS INTEGER)),
"2024년 11월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2024년 11월"::TEXT, ',', '')) AS INTEGER)),
"2024년 12월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2024년 12월"::TEXT, ',', '')) AS INTEGER)),
"2025년 1월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2025년 1월"::TEXT, ',', '')) AS INTEGER)),
"2025년 2월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2025년 2월"::TEXT, ',', '')) AS INTEGER)),
"2025년 3월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2025년 3월"::TEXT, ',', '')) AS INTEGER)),
"2025년 4월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2025년 4월"::TEXT, ',', '')) AS INTEGER)),
"2025년 5월" = to_jsonb(CAST(TRIM(BOTH '"' FROM REPLACE("2025년 5월"::TEXT, ',', '')) AS INTEGER))
WHERE
"2024년 8월"::TEXT LIKE '%"%' OR
"2024년 9월"::TEXT LIKE '%"%' OR
"2024년 10월"::TEXT LIKE '%"%' OR
"2024년 11월"::TEXT LIKE '%"%' OR
"2024년 12월"::TEXT LIKE '%"%' OR
"2025년 1월"::TEXT LIKE '%"%' OR
"2025년 2월"::TEXT LIKE '%"%' OR
"2025년 3월"::TEXT LIKE '%"%' OR
"2025년 4월"::TEXT LIKE '%"%' OR
"2025년 5월"::TEXT LIKE '%"%';
모든 DB가 원하는 형태로 정돈(cleansing) 되었다.

이제 다시 강의 내용으로 되돌아와, 원하는 필드에 있는 10개 값을 랜덤으로 출력하도록 하는 SQL쿼리를 입력했다. 그 결과 아래와 같이 랜덤 10개의 값이 추출되었다.

추가적으로 원하는 값을 자연어로 제미나이에게 설명한 후, 제미나이가 작성해준 'SQL쿼리'를 다시 supabase의 sql editor로 넣어, 원하는 값이 출력되는지 확인하였다.


이제 위의 프로세스를 n8n 워크플로우로 구성해본다. 다시 말해, 사용자가 DB에서 얻고자 하는 값을 자연어로 입력하면, Gemini와 같은 LLM을 거쳐 SQL쿼리를 생성하고, 해당 쿼리를 supabase로 보내서 원하는 값을 받아오는 워크플로우를 구성하는 것이다.
우선 아래와 같이 Open AI - message a model 노드를 생성하여, System - prompt에 테이블 상세 설명과 에이전트의 역할을 정의하는 내용을 입력하였고, User - prompt에 원하는 질문 ("가장 많은 개인간 거래가 발생한 지역은 어디인가?")을 자연어로 입력하였다.
그 결과 오른편 Output과 같이 Open AI가 SQL쿼리를 작성한 것을 확인할 수 있다.

-----
위와 같이 예제 실습을 하는 과정에서, 최근 나의 궁금증 "전체 부동산 거래 중에서 공인중개사를 거치지 않은 '직거래' 건수에 대해 알 수 있을까?"를 해결하기 위해서, 데이터 셋과 프롬프트를 변경하여 동일한 절차를 다시 진행하였다.
-----
그 결과, 아래와 같이 워크플로우를 작성하였고, 이를 기반으로 SQL 결과값도 확인할 수 있었다. 흥미로운 점은 2025년 6월 15일부터 2025년 7월 14일, 총 한 달 간 '직거래'가 가장 많이 일어난 곳은 수도권이 아닌 지방이라는 점이다. (반면 주택 매매의 약 80%는 서울에서 일어나고 있다. 매매의 절대숫자는 매우 큼에도 불구하고, 직거래 숫자가 매우 적다는 점은 특기할 만하다.)
*현재까지 작업을 수행해보았을 때, 직관에 반하는 결과를 확인할 수 있었고, 이를 기반으로 의미있는 분석 결과를 얻을 수 있겠다는 생각이 들었다.


그 다음으로는 n8n 워크플로우에서 supabase DB를 접속하도록 하기 위해서 'connect'를 클릭하여 DB정보를 확인한다.

Postgres 노드를 추가하여, 앞 노드에서 생성한 SQL쿼리를 추가하였다. 그 결과 아래와 같이 SQL쿼리를 통한 데이터가 도출됨을 확인할 수 있었다.

먼저 SQL 코드를 받아서 Postgres에서 실행하도록 하는 1번 워크플로우를 생성했다.
[1번 워크플로우: SQL코드를 받아 DB를 조회하는 워크플로우]

[2번 워크플로우: 사용자로부터 값을 입력받아, DB를 조회하는 워크플로우]


직거래 건 수 2,357건 + 중개거래 33,064건의 총 합은 35,421건인데, 전체거래는 2건이 더 많은 35,423건이었기 때문이다. 이 2건의 유실은 어디서 발생했는지 찾아보니, 두 개 데이터 상에서의 값이 각각 '중개���래'와 '중��거래'로 잘못 인코딩 되어 있음을 발견했다.
추가적으로 전체 35,423건의 데이터 중에서, 거래유형 외에도 '�'와 같은 특수문자가 입력된 것이 있는지 살펴보았다.
그 결과 다음과 같이, 거래유형 이외에도 특수문자로 잘못 인코딩된 레코드가 존재했다.


이 발견이 매우 중요한 이유는, 이러한 오류 부분이 데이터 분석 결과물의 신뢰도를 좌우할 수 있기 때문이다. '�'와 같은 특수기호가 어떤 과정에서 대체된 것인지는 모르겠다. 그러나 원본 csv 파일에서는 이와 같은 문제가 없는 것을 보면, supabase로 변환하는 과정에서 문제가 생긴 것은 아닌지 싶다.
몇 차례 csv file import를 더 해보면, 동일 record에서만 '�' 오류가 발생하는지, 아니면 매번 다른 레코드에서 '�' 변환 에러가 발생하는지 패턴을 확인해서, 원 데이터의 문제인지 아니면 supabase 변환 시의 문제인지를 확인할 수도 있을 것이다. 오류 생성의 패턴 확인을 위해서, 동일한 csv 파일로 '아파트 실거래2'라는 새로운 table을 생성하였다.
확인해보니 첫번째 테이블(아파트 실거래)와 두번째 테이블(아파트 실거래2)의 오류 생성 패턴이 동일한 것을 확인할 수 있다. 이렇게 되면 supabase 변환 상의 문제라기보다는, 원 데이터소스 상의 문제로 보는 것이 타당하다.
다행히도 오류 발생으로 인한 특수기호가 '�'로 한정되고 있다보니, AI가 자체적으로 �와 같은 특수기호를 실제 데이터로 makeup 할 수 있는지 테스트 해야한다. 만약 AI가 다른 데이터 값을 토대로 오류를 자체적으로 수정할 수 있다면 data cleansing 관점에서 매우 시간절약을 할 수 있고 결과 신뢰도 또한 향상 시킬 수 있기 때문이다.
테스트 결과, 지역정보(시군구, 거래유형, 중개사소재지)의 경우에는 매우 정확하게 수정하였다. 그러나 아파트 단지명의 경우에는, '청구'를 '청솔'로, '디에트르더클래스'를 '디스트르더클래스'로 잘못 수정(환각효과로 인한 문제) 하였다.

이러한 환각효과가 발생한 이유는, 단지 이름의 경우에는 비교적 시/군/구의 지리적 데이터에 대해 LLM이 정확한 값을 복구하는 것이 쉬웠을 것이나, 아파트 단지명의 경우에는 '청솔'인지 '청구'인지 제대로 파악할 수 있는 방법이 없거나 어려웠을 것이기 때문이다.
(사실 단지명의 경우에도, 시군구 데이터까지를 쌍(pair)으로 묶어서, 33000개의 전체 데이터 중에서 동일 시군구에 위치해있는 가장 유사한 단지명을 찾아서, 그것을 기반으로 복구한다면 훨씬 정확도가 높아질 것이다. 동일한 시군구에 '청솔'단지와 '청구'단지가 함께 있지 않는 한 말이다.)
우선 GPT가 오류를 복구해낼 수 있는 역량을 대략 확인하였으니, 추후 데이터 분석의 정확도를 높이기 위해서는, 기존 n8n 워크플로우 상에 IF 노드를 구성하여, 만약 DB 상에 �라는 문자가 존재하는 경우, '시군구'에 한하여 정보를 복구하여 답해달라는 요청을 할 수 있다.
(더 근본적으로는 왜 csv 파일이 깨졌는지, 본래 국토부 데이터 상에서도 깨져있는 파일이 올라간 것인지, 아니면 csv 다운로드 후 이 파일을 엑셀로 여는 과정에서 오염된 것인지를 확인하고 문제를 찾아 없애야한다.)
우선 이번 복습의 목표는 놓쳤던 예제 실습에 있기 때문에, 다시금 본 궤도로 복귀하여 이후 SQL 강의를 완료하도록 한다.
마지막 내용은 n8n 워크플로우를 통해 추출한 결과값을 console 등에 기록으로 남기기 위한 워크플로우 구성도 할 수 있다는 내용이다. (이 부분에 대해 강의에서 상세히 다루고 있진 않다.)

위 워크플로우에 따르면, SQL쿼리를 통해 도출한 값들을 엑셀시트로 변환시킨 후 구글 드라이브에 저장하여, 드라이브 링크를 output으로 출력하도록 할 수 있다. 이 때 Code2 내용의 경우에는, 쿼리로 나온 데이터 중 상위 몇 개 데이터를 예시로서 상위에 출력하도록 하는 내용이다.

이상 SQL 예제 수행 및 수행 과정에 생긴 여러 궁금증들을 함께 다뤄보았다.
다음에는 아래 예제를 다뤄보겠다.
16) 복습 - 예제#2. Pinecone 통한 벡터 임베딩 실습이 포함된 '12강' 내용 복습



댓글
댓글 쓰기